DF BIT IN IPSEC TUNNEL MODE:
By default, DF bit from INTERESTING TRAFFIC is copied to OUTER IP HEADER imposed by IPSEC END POINT.
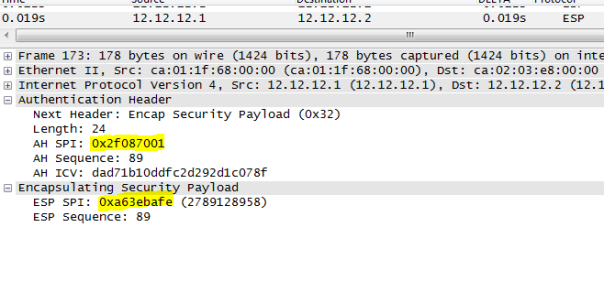
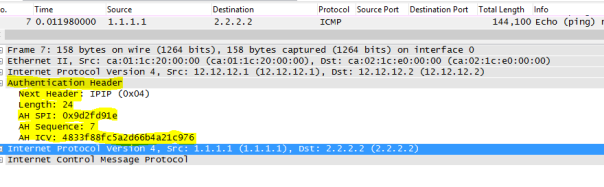
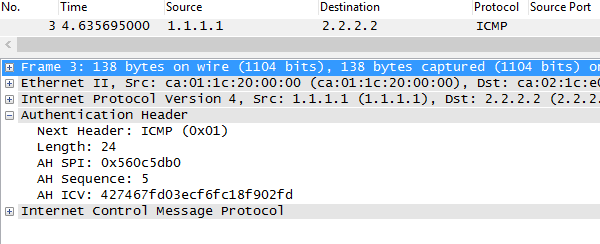
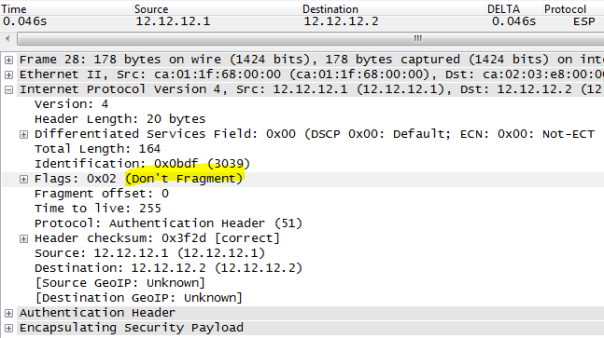
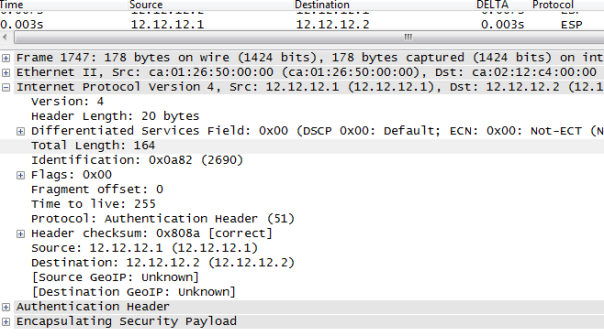
Below is the capture of ping from 1.1.1.1 to 2.2.2 with DF bit set , INTERESTING TRAFFIC:
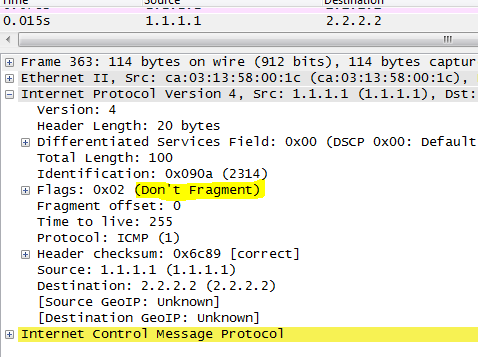
R1 and R2 are IPSEC END POINT ( TUNNEL MODE), below we can see DF bit is copied into OUTER IP HEADER:
CHECKING IF PACKETS ARE BEING ENCRYPTED/HASHED AND DECRYPTED/ VERIFIED
R1#show crypto ipsec sa peer 12.12.12.2
interface: FastEthernet0/0
Crypto map tag: ZEE, local addr 12.12.12.1
protected vrf: (none)
local ident (addr/mask/prot/port): (1.1.1.1/255.255.255.255/0/0)
remote ident (addr/mask/prot/port): (2.2.2.2/255.255.255.255/0/0)
current_peer 12.12.12.2 port 500
PERMIT, flags={origin_is_acl,}
#pkts encaps: 11720, #pkts encrypt: 11720, #pkts digest: 11720
#pkts decaps: 11718, #pkts decrypt: 11718, #pkts verify: 11718
pkts digest: 11720 shows message being hashed
pkts verify: 11718 shows messages received are being checked for hash and found to have correct hash .
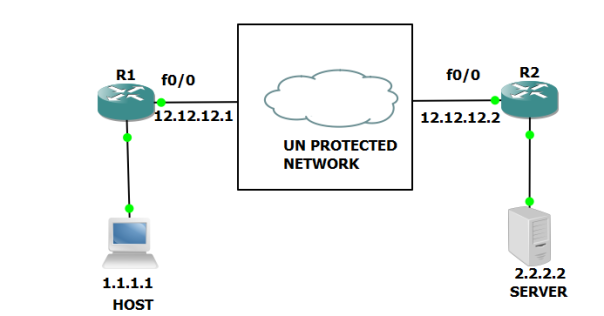
CHANGING IPSEC MODE FROM TUNNEL TO MODE WONT TAKE EFFECT IN SOME CASES:
An IPSEC END point determines if the CURRENT TUNNEL MODE should be allowed to change to TRANSFORM MODE or NOT based on LOCAL PROXY ID.
EXAMPLE:
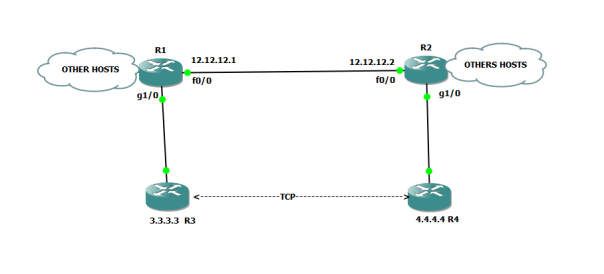
Above R1 and R2 are IPSEC END POINTS in Tunnel mode.
let change the mode to TRANSFOR MODE using :
R1(config)#crypto ipsec transform-set ZEE ah-md5-hmac esp-des
R1(cfg-crypto-trans)#mode transport
R2(config)#crypto ipsec transform-set ZEE ah-md5-hmac esp-des
R2(cfg-crypto-trans)#mode transport
We clear PHASE1 and PHASE2 on R1/R2:
R1#clear crypto isakmp
R1#clear crypto sa
R2#clear crypto isakmp
R2#clear crypto sa
We initiate INTERESTING TRAFFIC FROM 1.1.1.1 to 2.2.2.2
Note even though we change the mode to TRANSPORT but the command was rejected without any notification from IOS.
R1#show crypto ipsec sa
interface: FastEthernet0/0
Crypto map tag: ZEE, local addr 12.12.12.1
protected vrf: (none)
local ident (addr/mask/prot/port): (1.1.1.1/255.255.255.255/0/0)
remote ident (addr/mask/prot/port): (2.2.2.2/255.255.255.255/0/0)
inbound esp sas:
spi: 0xE22F19EC(3794737644)
transform: esp-des ,
in use settings ={Tunnel, }
outbound esp sas:
spi: 0x8996DB7F(2308365183)
transform: esp-des ,
in use settings ={Tunnel, }
R2#show crypto ipsec sa
interface: FastEthernet0/0
Crypto map tag: ZEE, local addr 12.12.12.2
protected vrf: (none)
local ident (addr/mask/prot/port): (2.2.2.2/255.255.255.255/0/0)
remote ident (addr/mask/prot/port): (1.1.1.1/255.255.255.255/0/0)
inbound esp sas:
spi: 0x8996DB7F(2308365183)
transform: esp-des ,
in use settings ={Tunnel, }
outbound esp sas:
spi: 0xE22F19EC(3794737644)
transform: esp-des ,
in use settings ={Tunnel, }
Tunnel mode remains ” TUNNEL” .
Basically IPSEC END POINT say uses this LOGIC :
If the PROXY ID shows the INTERESTING TRAFFIC is TRANSIT traffic , the traffic passing through the ROUTER, then MODE can not be set for TRANSPORT MODE on the router.
On the other hand if PROXY ID shows the ” INTERESTING TRAFFIC” is actually matches the IPSEC TUNNEL SRC and DEST, then MODE can be allowed to change to TRANSPORT MODE.
For e.g :
R1 has PROXY ID”access-list permit ip host 12.12.12.1 host 12.12.12.2″ , Since R1 is source PHASE1/PHASE2 with 12.12.12.1 and peer as 12.12.12.2, MODE therefore can changed to ” TRANSPORT” mode via CLI’s command.
R1 and R2 configured with:
crypto ipsec transform-set ZEE ah-md5-hmac esp-des
mode transport
R1#show crypto ipsec sa
interface: FastEthernet0/0
Crypto map tag: ZEE, local addr 12.12.12.1
protected vrf: (none)
local ident (addr/mask/prot/port): (12.12.12.1/255.255.255.255/0/0)
remote ident (addr/mask/prot/port): (12.12.12.2/255.255.255.255/0/0)
inbound esp sas:
spi: 0x4D47EBA4(1296559012)
transform: esp-des ,
in use settings ={Transport, }
outbound ah sas:
spi: 0x22832CF(36188879)
transform: ah-md5-hmac ,
in use settings ={Transport, }
R2
R2#show crypto ipsec sa
interface: FastEthernet0/0
Crypto map tag: ZEE, local addr 12.12.12.2
protected vrf: (none)
local ident (addr/mask/prot/port): (12.12.12.2/255.255.255.255/0/0)
remote ident (addr/mask/prot/port): (12.12.12.1/255.255.255.255/0/0)
inbound esp sas:
spi: 0x349834B2(882390194)
transform: esp-des ,
in use settings ={Transport, }
outbound esp sas:
spi: 0x4D47EBA4(1296559012)
transform: esp-des ,
in use settings ={Transport, }
Below we can see Tunnel mode has been changed to TRANSPORT MODE.
How about if we change the tunnel mode back to tunnel mode while keeping PROXY ID same?
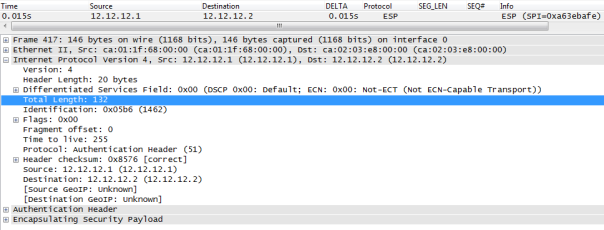
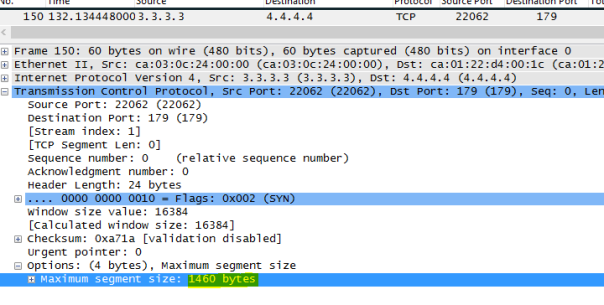
It will introduce another OUTER IP HEADER ( 12.12.12.1–12.12.12.2) to encapsulate INNER PACKET ( 12.12.12.1 –12.12.12.2) so it servers no purpose but yes it can be done. Below we can see ” INTERESTING TRAFFIC 12.12.12.1—-12.12.12.12 is encrypted then R1 imposes OUTER IP HEADER SRC 12.12.12.1 DEST 12.12.12.2. note the packet length of 164 bytes.
So we just added 20 bytes extra overhead( OUTER IP HEADER) by using tunnel mode when TRANSPORT could have been used instead.
KEY POINT: Mode can be changed from TUNNEL to TRANSPORT using CLI command If PROXY ID matches IPSEC TUNNEL SRC and IPSEC TUNNEL DEST on the LOCAL ROUTER.
If not mode remains tunnel, command will be rejected without any notice by IOS.
Next we will go over DEAD PEER DETECTION.
DEAD PEER DETECTION:t
Let first see the issue we are trying to solve with DEAD PEER DETECTION.
IPSEC SA ‘s lifetime is 60 MIN by default on Cisco Router. SA will be maintained until 60 MIN elapsed. IPSEC END POINTS, being connected over a IP TRANSPORT may encounter IP REACHBILITY ISSUE ( some Switch or link on the path inside the IP TRANSPORT was down) but SA will be erroneously maintained in SA database causing INTERESTING TRAFFIC to be black holed until LIFETIME of SA , which is undesirable.
It is obvious we need a mechanism between ISPEC peers to detect if they are reachable/alive.
Various vendors come with their own solutions . Let explore some of them so we can better appreciate DEAD PEER DETECTION.
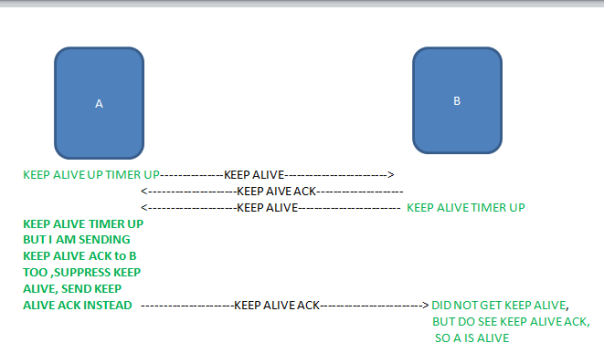
HEAR BEAT TECHNIQUE:
IPSEC AB IPSEC B
A sends hello at regular interval so A needs to maintain a TIMER for that.
On the other hand, B needs to maintain a separate TIMER which defines the MAX TIME B can wait to wait for HELLO from A, if none received within that MAX TIME, B should consider A dead and should purge SA.
Recall that SA are unidirectional, so above B correctly detect A is no longer reachable because it did not receive HELLO from A within SET MAX TIME. But A will continue to send traffic over SA towards B . Again causing INTERESTING TRAFFIC to be black holed.
In order for this scheme to be effective B too needs to send HELLO at regular INTERVAL thus B needs to maintain a TIMER for that. A needs also needs to maintain a TIMER which define MAX TIME that A can wait to receive HELLO from B before considering B as dead and purging SA towards B ( outbound SA). Both A and B must need to agree on common MAX TIME OUT FOR HELLO. Such scheme are used by EIGRP, OSPF , both of which uses a HELLO INTERVAL and some TIMEOUT value.
So in above scheme we see following issues:
Both party needs to exchange some info about the HELLO INTERVAL and MAX TIMEOUT for hello. Both needs to maintain two separate TIMERS : One for hello interval, the other MAX TIME OUT for hello.
How about if we have not just one but 50,000 IPSEC tunnels ( e.g VPN Concentrator at HQ and thousands of remote locations connected to HQ over IPSEC)
That will mean HQ and REMOTE LOCATIONS needs to exchange 100K messages ( 50,000 Hello from HQ to REMOTE LOCATIONS, 50,000 Hello to HQ) which does not scale well.
KEEP ALIVE TECHNIQUE:
This technique is designed to overcome the limitation of ” HEART BEAT TECHNIQUE” described above.
With that scheme, we cut down a number of messages exchanges to some extent but both party has still need to maintain two timers. BGP uses the same scheme where KEEP ALIVE is suppressed to a particular peer if BGP update is being sent to that PEER which proves itself the peer is alive.
Again the this scheme is not scalable when implemented on IPSEC ENDPOINT with thousands of IPSEC TUNNELS.
Cisco implement this scheme somewhat differently in that ” KEEP ALIVE are sent at regular interval, transmission of KEEP ALIVE ACK does not suppress KEEP ALIVE as we discussed above.
KEEP ALIVE message here is R U THERE ?
KEEP ALIVE ACK messge here is R U THER ACK ?
crypto isakmp keepalive 10 2 periodic
Router sends R u there? every 10 sec, if R U THERE ACK not received in 10 SEC, then R u there ? messages are sent every 2 sec. Peer will try to send 4 to 5 messages if no response is received, remote peer is declared dead. IN COMING SA for that PEER is purged. This happens even if local peer is receiving INTERESTING TRAFFIC ON INCOMING SA FROM REMOTE PEER. The sole criteria to declare REMOTE PEER dead is not to receive ” R U THERE ACK from that peer this is the key difference Cisco ‘s implementation of ” KEEP ALIVE” technique discussed above.
For optimal design, both peers must be configured with that feature otherwise traffic will be black holed if remote peer does not implement it and therefore does not require LOCAL PEER to prove its liveliness which cause remote peer to continue to send traffic to local peer (which is no longer alive) until lifetime for SA is up .
ENTERS DEAD PEER DETECTION
Both party will are free to to query if there is question the other party is not alive at any time. There is no need to send any message at regular interval to prove liveliness to the peer.
This is how the whole scheme works.
Two messages are used:
R U THERE ?
R U THERE ACK
If a peer is receiving INTERESTING TRAFFIC over SA, then the traffic itself proves the SENDER is alive, thus SENDER does not need to send any message to prove its liveliness.
How ever if a peer( A) has to send some traffic to the peer ( B) but A does not see any traffic for specific amount of time( aka worry metric), then A needs to first verify if B is alive by sending a ” R U THERE ISKAMP MESSAGE to B. B then needs to send R U THERE ACK to A to prove its liveliness.
The specific amount of time mentioned above is left to VENDOR as per RFC 3706
The beauty of this scheme Production traffic itself is used to prove liveliness , message R U THERE ? is only sent if there is no incoming production traffic for set amount of time ( WORRY METRIC) on a particular SA from a PEER and there is INTERESTING NEED TO BE SENT TO THAT PARTICULAR PEER, (which drastically cut down the amount of messages) needed to prove liveliness.
Also both party has to maintain just one timer ( worry metric), the maximum amount of idle time to wait when there is no traffic being received from a particular peer before sending ” R U THERE ? message to verify remote peer’s liveliness.
HOW DO WE CONFIGURE IT ?
crypto isakmp keepalive XX YY on-demand
Above XX is the MAX IDLE TIME local PEER can wait before sending R U THERE ? message to remote peer to prove its liveliness by sending R U THERE ACK
If R U THERE ACK is not received with in XX time, then LOCAL PEER will send R U THERE ?every YY SEC, after sending some messages without any response ( response could be incoming traffic from that remote peer or RU THERE ACK) , Remote peer is declared dead and INBOUND SA ASSOCIATED WITH REMOTE PEER is purged.
For best design, DPD should be configured on both end, it is possible to configure DPD on one end and still have PHASE1/PHASE2.